AI startup company - Large model training
Scenario
A startup company focused on generative AI aims to develop a powerful text generation model and provide it as a SaaS service to other businesses.
1. Register and Create Instances:
After registering an account on NiceGPU, the company applied for several computing nodes equipped with high-performance GPUs based on the scale of the model and training duration, forming a Ray cluster.

- What is NCU?
- 1 NCU is equivalent to the computational power of one A100 GPU that you can use continuously for 24 hours on our platform.
- AI startup companies often involve more complex and large-scale AI model training and deployment. Therefore, the demand for computing power is also much greater. Here are some examples of typical scenarios:
- Large-scale language model (LLM) training:
- Task: Train large language models similar to GPT-3, capable of generating text, translating, writing code, and more.
- Required NCU: Hundreds or even thousands of NCUs. LLMs have huge parameter counts and require vast amounts of training data, necessitating significant computing power.
- Scenario: Develop general-purpose AI assistants, intelligent customer service, content generation tools, etc.
- Multimodal large model training:
- Task: Train models capable of handling multiple modalities of data, including text, images, and videos.
- Required NCU: Hundreds of NCUs. Multimodal models involve various types of data and complex structures, requiring substantial computing resources.
- Scenario: Develop AI painting tools, video generation tools, virtual humans, etc.
- Distributed training:
- Task: Distribute model training tasks across multiple GPUs to accelerate the training process.
- Required NCU: Depends on the model size and distribution strategy, typically requiring dozens to hundreds of NCUs.
- Scenario: Train ultra-large scale models, accelerate experimental iterations, etc.
- Factors affecting NCU demand, aside from model size and data volume, include the following:
- Model architecture: Different architectures like Transformer and CNN models have varying computational resource requirements.
- Optimization algorithms: Different optimization algorithms vary in their efficiency in utilizing computational resources.
- Hardware configuration: GPU models, memory size, and other hardware configurations impact training speed.
- Distribution strategy: Different distribution strategies such as data parallelism and model parallelism have varying impacts on communication overhead and resource utilization rates.
2. Data and Code Preparation:
- Data preparation: The company collected a massive amount of text data, cleaned and preprocessed it to form a format suitable for model training.
- Code development: The company's AI engineers used PyTorch and the Transformers framework to develop training code for large-scale language models based on the Transformer architecture.
3. Configuring Ray Cluster:
- Resource Allocation: The company allocated CPU, GPU, memory, and other resources from compute nodes to the Ray cluster.
- Distribution Strategy: The company utilized Ray's distributed data parallelism (DDP) and model parallelism (MP) technologies to partition models and data across multiple GPUs, accelerating the training process.
- Fault Tolerance: The company configured Ray's fault tolerance mechanisms to ensure that training tasks can automatically recover in the event of a failure.
4. Starting Training Tasks:
- Task Submission: The company submits training tasks to the Ray cluster, and Ray automatically schedules these tasks, distributing the computational load across various nodes.
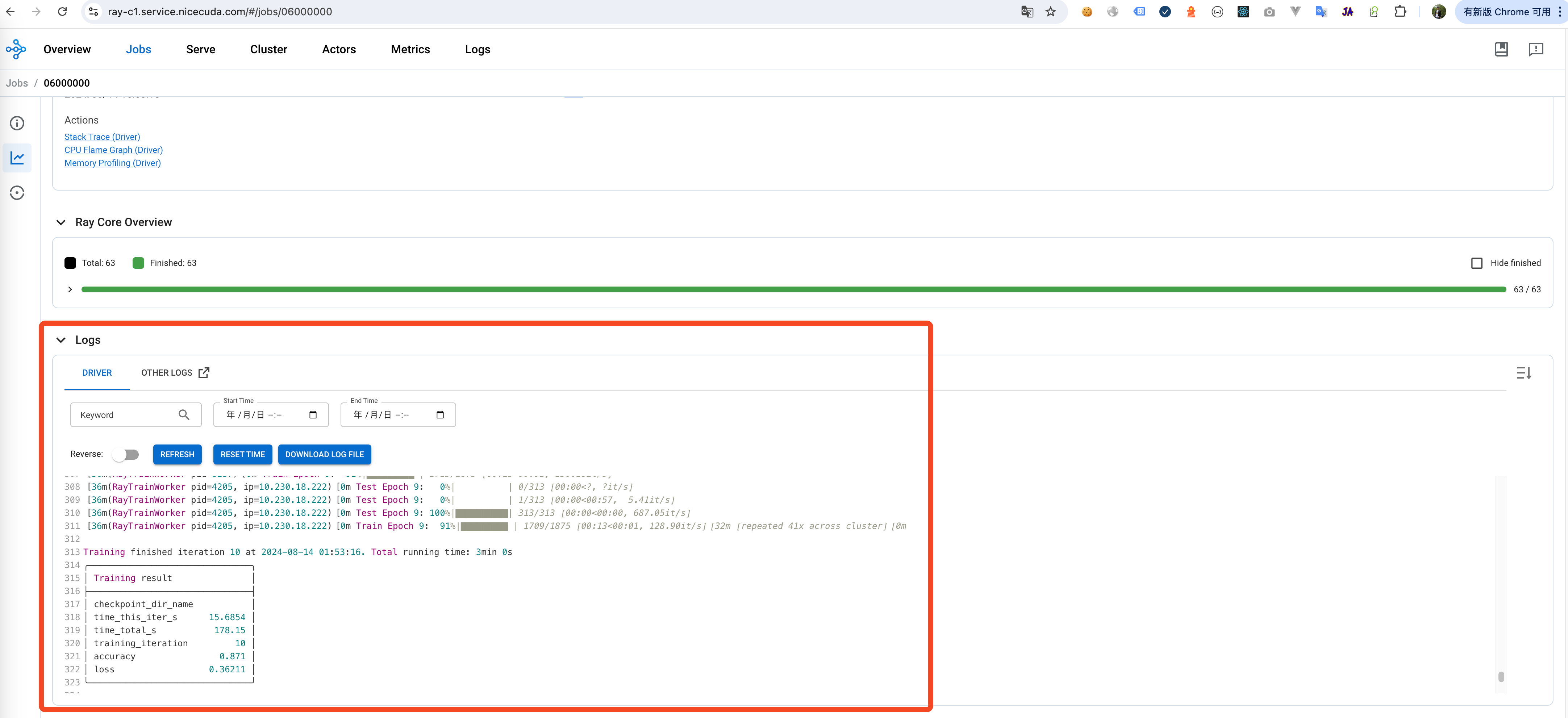
- Monitoring Training Process: The company monitors the training progress in real-time through Ray's monitoring panel, including metrics like training loss and perplexity.
import ray from transformers import AutoModelForSeq2SeqLM # connect to Ray Cluster ray.init(address="auto") # Distributed Data Parallelism @ray.remote class TrainTask: def __init__(self, config, data_loader): self.model = AutoModelForSeq2SeqLM.from_config(config) self.data_loader = data_loader def train_epoch(self): # Code for training one epoch pass # ... (Remaining code omitted)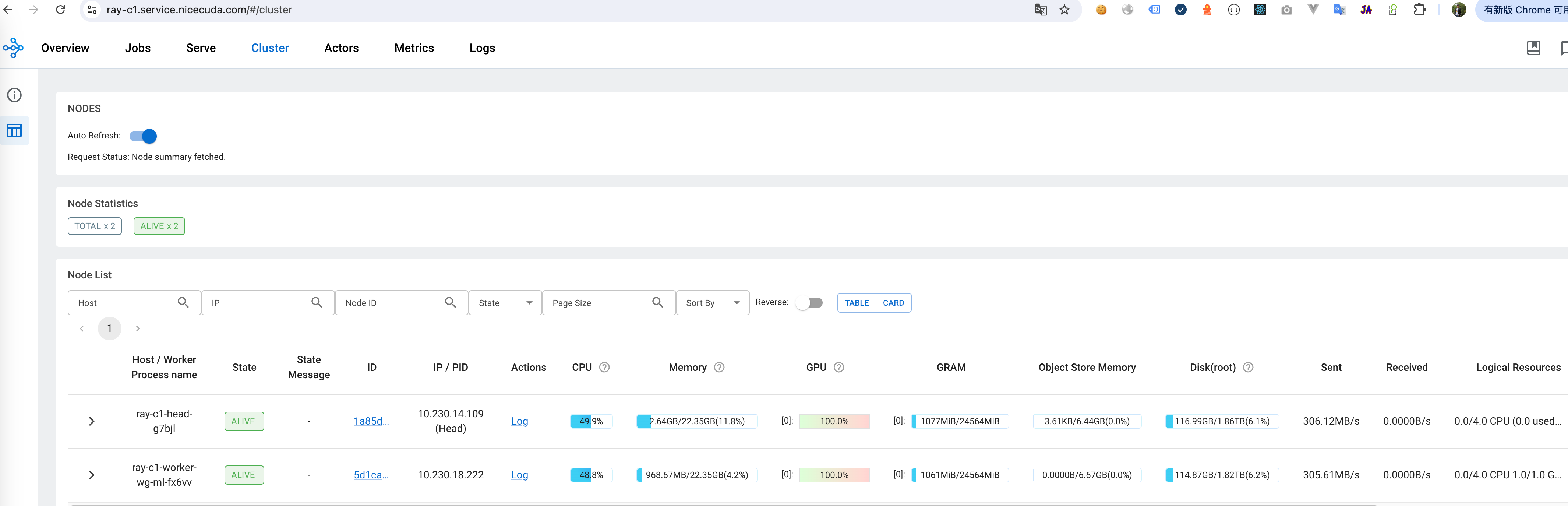
5. Model Saving and Deployment:
- Model Saving: After completing the training, the company saves the trained model to cloud storage.
- Model Deployment: The company uses frameworks such as FastAPI or Flask to deploy the model as a RESTful API, providing services to external users.
- Containerization: The company containerizes the model service and deploys it on a container orchestration platform (such as Kubernetes) to achieve automatic scaling and high availability.
6. Providing SaaS Services:
- API Exposure: The company exposes the model services through an API gateway, allowing other enterprises to call the model via API to generate text.
# Deployment as API Service: from fastapi import FastAPI from transformers import pipeline app = FastAPI() generator = pipeline("text-generation", model="saved_model") @app.post("/generate") def generate_text(prompt: str): result = generator(prompt, max_length=100) return {"generated_text": result[0]["generated_text"]}
7. Summary:
By leveraging the shared computing platform and Ray cluster, this AI startup successfully trained a large-scale language model and deployed it as a SaaS service, achieving commercialization.
This case demonstrates the critical role of NiceGPU in AI model training and deployment, providing AI startups with fast, flexible, and scalable solutions.