Ray 案例介绍
小李是某科技公司的一名数据科学家,公司正面临处理海量数据和加速机器学习模型训练的需求。 为了提升计算效率,他选择使用 Ray 分布式计算框架,通过 NiceGPU 多节点 RayCluster 集群,快速使用大规模并行计算平台。
1. 注册并创建实例
小李在NiceGPU审批了 VIP 账号后,使用10 NCU创建一个配置为 4 张 NVIDIA RTX 4090 的实例, 使用 RayCluster 应用模板。

- 什么是NCU?
- 1 NCU 等于您可以在我们平台上连续使用24小时的一块A100 GPU的算力。
- 针对NCU的使用场景和对应任务量举例:
- 分布式训练:
- 任务: 将模型训练任务分布到多个GPU上,加速训练过程。
- 所需NCU: 根据模型规模和分布式策略而定,通常需要多个NCU。
- 影响NCU需求的因素:
- 模型复杂度: 模型参数量越大,计算量越大,所需的NCU越多。
- 数据集大小: 数据集越大,训练时间越长,所需的NCU越多。
- 训练精度: 要求更高的训练精度,通常需要更多的训练迭代次数,从而消耗更多的计算资源。
- 模型优化算法: 不同的优化算法对计算资源的需求也不同。
2.客户端 Ray 依赖安装
pip install -U "ray[default]"
3.编写测试代码
Train a PyTorch Model on Fashion MNIST(More GPU)
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
# time: 2024/7/10 14:15
# file: ray_train_MNIST.py
# @Author : Json.J.Hu
# @Version:V 0.1
# @desc : Train a PyTorch Model on Fashion MNIST
# 这部分导入了训练过程中所需要的各种库,包括PyTorch、Ray、以及用于数据处理的torchvision。FileLock用于在多进程环境中安全地处理文件。
import os
from typing import Dict
import torch
from filelock import FileLock
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.transforms import Normalize, ToTensor
from tqdm import tqdm
import ray.train
from ray.train.torch import TorchTrainer
from ray.train import ScalingConfig, RunConfig
# 1.定义你的 runtime 环境,包括所需的 Python 包
runtime_env = {
"pip": ["numpy", "torch","torchvision"]
}
# 2. 数据加载器函数(可以读取github,huggingface等数据集)
'''
这个函数通过torchvision.datasets从网上下载Fashion MNIST数据集,
并将其转换为PyTorch的DataLoader对象,用于后续的模型训练和测试。
数据经过了标准化(均值为0.5,标准差为0.5)处理。
'''
def get_dataloaders(batch_size):
# Transform to normalize the input images
transform = transforms.Compose([ToTensor(), Normalize((0.5,), (0.5,))])
with FileLock(os.path.expanduser("~/data.lock")):
# Download training data from open datasets
training_data = datasets.FashionMNIST(
root="~/data",
train=True,
download=True,
transform=transform,
)
# Download test data from open datasets
test_data = datasets.FashionMNIST(
root="~/data",
train=False,
download=True,
transform=transform,
)
# Create data loaders
train_dataloader = DataLoader(training_data, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
return train_dataloader, test_dataloader
#3. 定义神经网络模型
'''
这是一个简单的多层神经网络,用于对Fashion MNIST数据集进行分类。
它包含了两个隐藏层,每个隐藏层之后都有ReLU激活函数和Dropout层,
最后一层将数据映射到10个类别(对应Fashion MNIST的10个标签)。
'''
# Model Definition
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Dropout(0.25),
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.25),
nn.Linear(512, 10),
nn.ReLU(),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
# 4.定义训练函数
'''
该函数是每个工作节点的训练函数,包含以下几个主要步骤:
1).获取数据加载器
2).准备数据加载器和模型以支持分布式训练
3).使用交叉熵损失函数和随机梯度下降优化器进行训练
4).在每个epoch结束时,评估模型的表现并通过ray.train.report报告损失和准确率
'''
def train_func_per_worker(config: Dict):
lr = config["lr"]
epochs = config["epochs"]
batch_size = config["batch_size_per_worker"]
# Get dataloaders inside the worker training function
train_dataloader, test_dataloader = get_dataloaders(batch_size=batch_size)
# [1] Prepare Dataloader for distributed training
# Shard the datasets among workers and move batches to the correct device
# =======================================================================
train_dataloader = ray.train.torch.prepare_data_loader(train_dataloader)
test_dataloader = ray.train.torch.prepare_data_loader(test_dataloader)
model = NeuralNetwork()
# [2] Prepare and wrap your model with DistributedDataParallel
# Move the model to the correct GPU/CPU device
# ============================================================
model = ray.train.torch.prepare_model(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9)
# Model training loop
for epoch in range(epochs):
if ray.train.get_context().get_world_size() > 1:
# Required for the distributed sampler to shuffle properly across epochs.
train_dataloader.sampler.set_epoch(epoch)
model.train()
for X, y in tqdm(train_dataloader, desc=f"Train Epoch {epoch}"):
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
test_loss, num_correct, num_total = 0, 0, 0
with torch.no_grad():
for X, y in tqdm(test_dataloader, desc=f"Test Epoch {epoch}"):
pred = model(X)
loss = loss_fn(pred, y)
test_loss += loss.item()
num_total += y.shape[0]
num_correct += (pred.argmax(1) == y).sum().item()
test_loss /= len(test_dataloader)
accuracy = num_correct / num_total
# [3] Report metrics to Ray Train
# ===============================
ray.train.report(metrics={"loss": test_loss, "accuracy": accuracy})
# 5. 主训练函数
'''
这个函数设置了分布式训练的相关配置,包括使用多少个工作节点(num_workers)和是否使用GPU(use_gpu),然后初始化并启动分布式训练。
该函数是整个训练过程的主函数,包含以下几个主要步骤:
1).配置训练参数
2).配置计算资源
3).初始化Ray TorchTrainer
4).开始分布式训练
'''
def train_fashion_mnist(num_workers=1, use_gpu=True):
global_batch_size = 32
train_config = {
"lr": 1e-3,
"epochs": 10,
"batch_size_per_worker": global_batch_size // num_workers,
}
# Configure computation resources
scaling_config = ScalingConfig(num_workers=num_workers, use_gpu=use_gpu)
# Initialize a Ray TorchTrainer
#run_config = RunConfig(storage_path="/mnt/shared_storage/ray_result")
trainer = TorchTrainer(
train_loop_per_worker=train_func_per_worker,
train_loop_config=train_config,
scaling_config=scaling_config,
#run_config=run_config # 指定存储路径
)
# [4] Start distributed training
# Run `train_func_per_worker` on all workers
# =============================================
result = trainer.fit()
print(f"Training result: {result}")
# 6.主函数: 运行训练任务
'''
这是整个训练过程的入口函数,包含以下几个主要步骤:
1).初始化Ray集群
2).调用train_fashion_mnist函数开始训练
'''
if __name__ == "__main__":
ray.init(runtime_env=runtime_env)
train_fashion_mnist(num_workers=2, use_gpu=True)
4 使用 Notebook 提交 Job
-
在 Notebook 中创建一个新的 Python3 的 Notebook ,编写 Python 代码
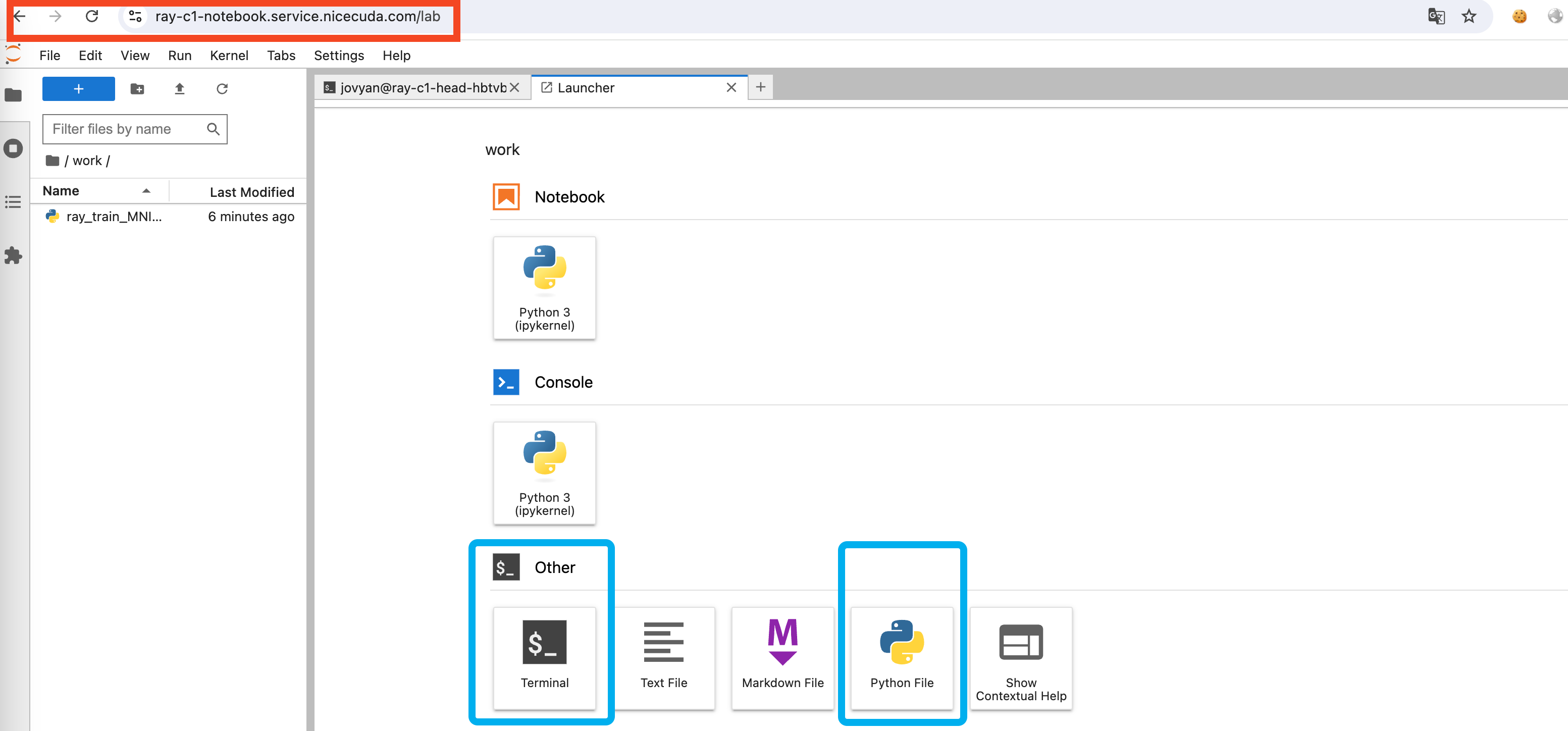
ray job submit --verify false --working-dir . -- python demo1.py
5.查询执行结果
-
监控 Dashboard 地址:https://ray-c1.service.nicegpu.com/#/cluster 中可以 GPU,CPU 等资源使用情况、RayCluster 集群节点健康情况。
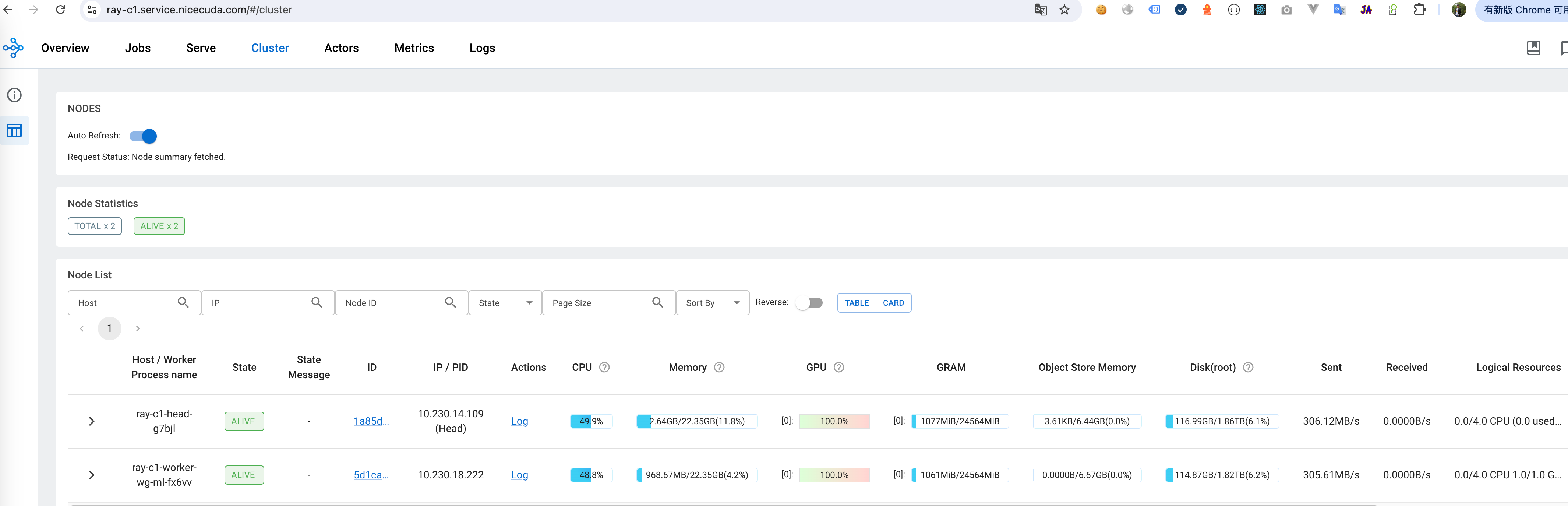
-
Dashboard -> Jobs 中可以查看当前执行 Job 的状态、日志等信息。 job 的 log 输出:
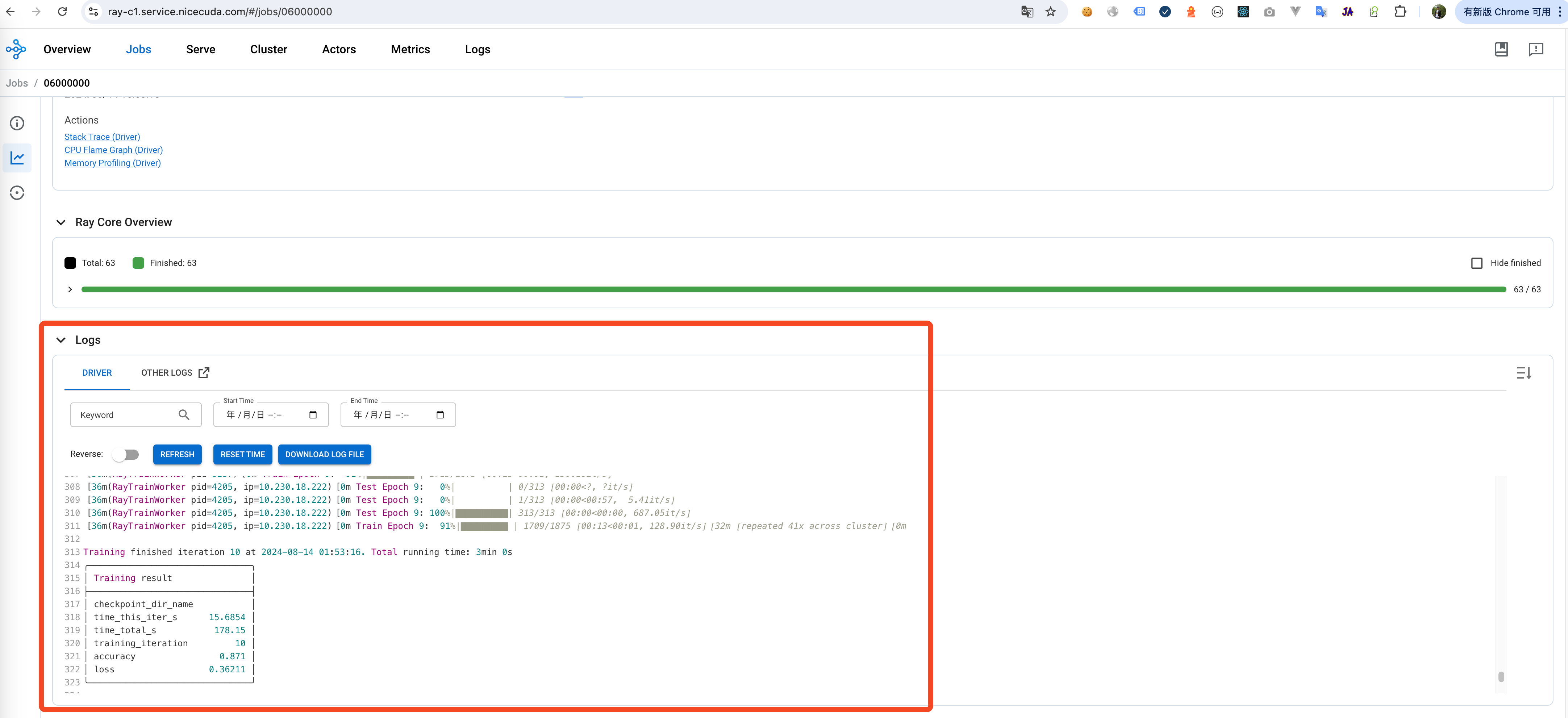
6.总结
- 通过 Ray 框架与共享算力平台的结合,小李成功构建了一个高效的分布式计算平台。
- 大幅提升了公司在数据处理和机器学习方面的能力。
- 同时,Ray 的灵活性使得平台易于扩展,满足未来更多计算任务的需求。