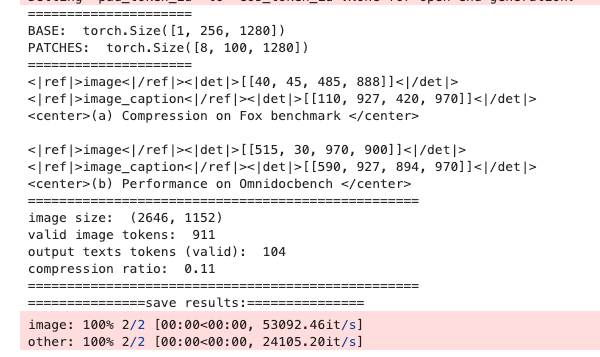
如何运行 DeepSeek-OCR 模型
本文档介绍如何在 NiceGPU 平台运行 DeepSeek-OCR 模型。
方式一:使用预编译的 DeepSeek OCR App 一键部署
在 AI 模型模板中选择预编译的 DeepSeek OCR App,支持一键部署,开箱即用。

该应用内置了 DeepSeek OCR 模型,提供现代化的 Web 界面(基于开源项目进行了安全性和用户体验优化)。
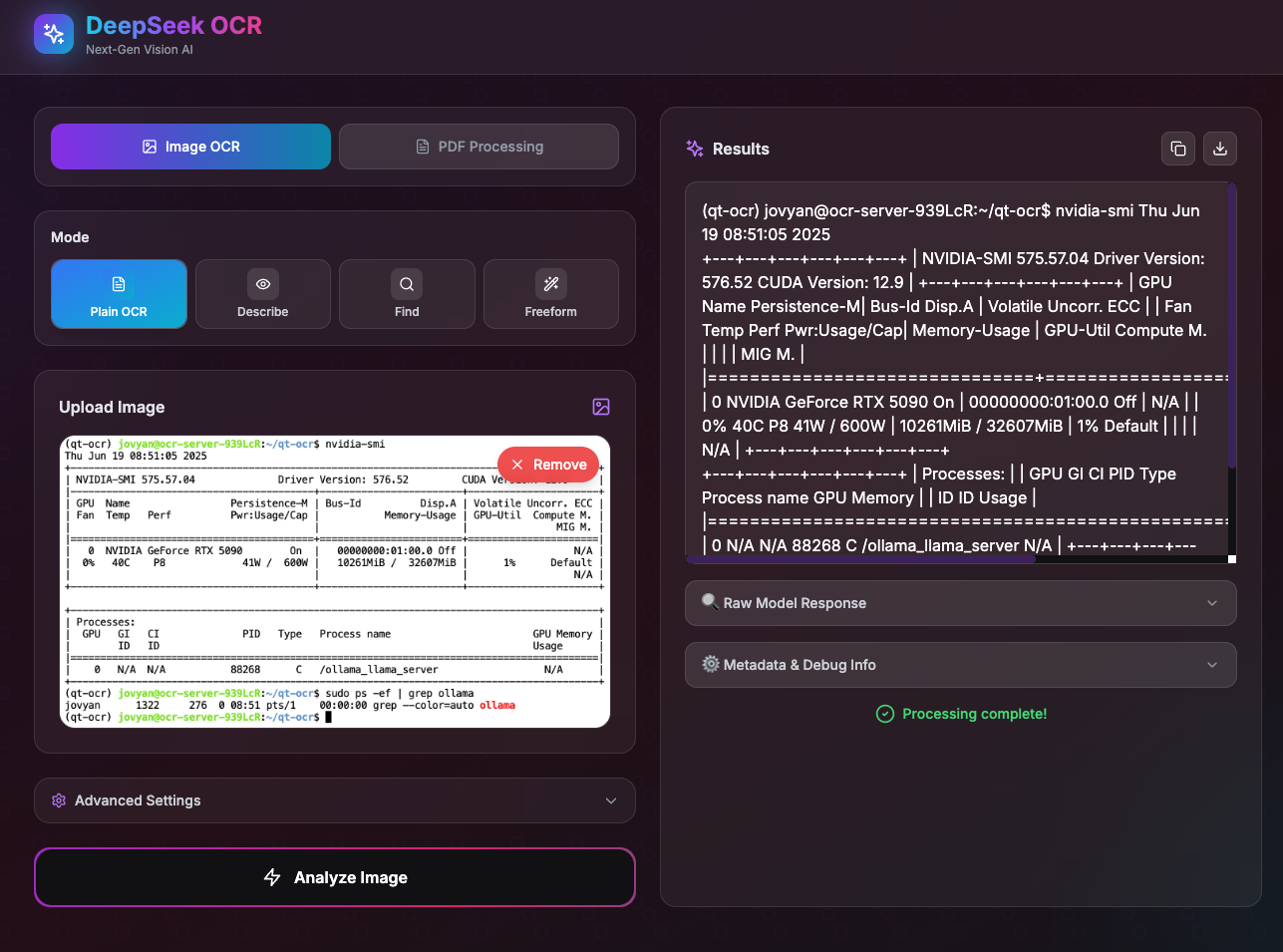
应用支持实时预览、进度显示和超时自动重连功能,确保良好的使用体验。
方式二:使用开发模板从零构建环境运行官方示例代码
如需自定义配置或进行二次开发,可以使用开发模板从零开始构建环境。您可以下载示例 Notebook 文件:deepseek-ocr.ipynb
1. 创建实例
在 NiceGPU 平台创建实例,配置如下:
- 模板选择:
PyTorch CUDA 12 - 显卡选择:RTX 5090 或 RTX 4090(推荐)
2. 安装基础依赖
# 注意:PyTorch 版本需要与 flash-attn 预编译版本兼容,建议使用预编译版本以避免长时间编译
pip install torch==2.8.0 transformers==4.46.3 tokenizers==0.20.3 einops addict easydict
3. 安装 CUDA 工具包(nvcc)
# 下载并安装 CUDA keyring
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
# 安装 CUDA 工具包 12.8
sudo apt-get -y install cuda-toolkit-12-8
# 验证安装
/usr/local/cuda-12/bin/nvcc --version
4. 安装 Flash Attention
# 重要:请使用预编译版本以避免长时间编译(参考:https://github.com/Dao-AILab/flash-attention/releases)
# 如使用源码编译,安装过程可能卡在 "Building wheel for flash-attn" 步骤,耗时约 5-15 分钟
export PATH=/usr/local/cuda-12/bin:$PATH && pip install flash-attn==2.8.3 --no-build-isolation
5. 安装其他依赖并运行示例代码
首先安装所需的 Python 包:
pip install tqdm ipywidgets pillow matplotlib torchvision
然后运行以下示例代码:
from transformers import AutoModel, AutoTokenizer
import torch
import os
# 设置使用的 GPU 设备
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True
)
model = model.eval().cuda().to(torch.bfloat16)
# 配置推理参数
# 提示词选项:
# - "<image>\nFree OCR. " # 基础 OCR
# - "<image>\n<|grounding|>Convert the document to markdown. " # 转换为 Markdown
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'fig1.png' # 请修改为您的图片路径
output_path = 'out-dir' # 请修改为输出目录路径
# 模型配置参数说明:
# - Tiny: base_size=512, image_size=512, crop_mode=False
# - Small: base_size=640, image_size=640, crop_mode=False
# - Base: base_size=1024, image_size=1024, crop_mode=False
# - Large: base_size=1280, image_size=1280, crop_mode=False
# - Gundam: base_size=1024, image_size=640, crop_mode=True
# 执行推理
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True
)
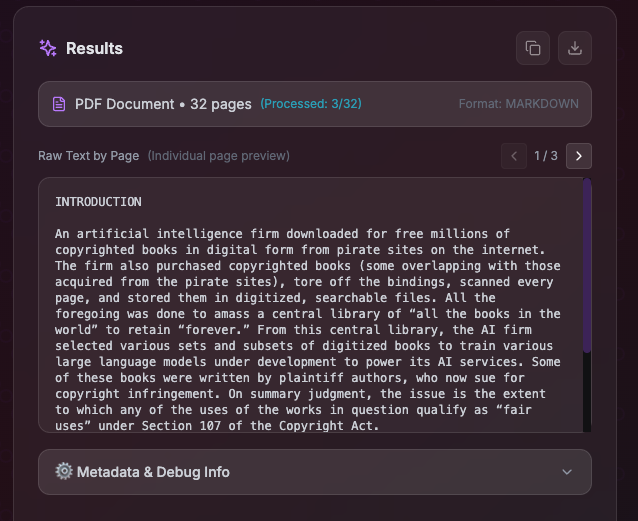
运行成功后,结果将保存到指定的输出目录。示例如下: