AI爱好者 - 探索ChatGLM
场景
小张是一位对 AI 深度学习充满热情的个人爱好者,他希望能够在不局限于自己电脑配置的情况下,尝试各种各样的 AI 模型,从图像生成到自然语言处理。
1. 注册并创建实例
小张在NiceGPU注册账号后,使用2 NCU创建一个配置为1张NVIDIA RTX 4090的实例, 使用ChatGLM应用模板。
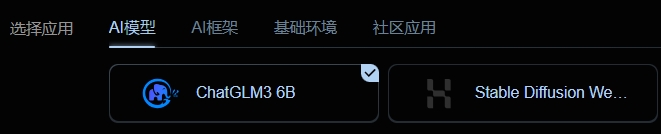
- 什么是NCU?
- 1 NCU 等于您可以在我们平台上连续使用24小时的一块A100 GPU的算力。
- 针对NCU的使用场景和对应任务量举例:
- 中型神经网络训练:
- 任务: 训练一个中等规模的计算机视觉模型(如物体检测)。
- 所需NCU: 2-5 NCU。中型模型对计算资源需求较高,需要更多的NCU来加速训练。
- 生成模型实验:
- 任务: 训练GAN、VAE等生成模型,生成图像、文本等。
- 所需NCU: 3-8 NCU。生成模型通常需要较大的模型和大量的训练数据,对计算资源要求较高。
- 强化学习算法实验:
- 任务: 训练强化学习智能体,解决各种控制问题。
- 所需NCU: 2-10 NCU。强化学习算法通常需要大量的实验和迭代,对计算资源需求较高。
- 影响NCU需求的因素:
- 模型复杂度: 模型参数量越大,计算量越大,所需的NCU越多。
- 数据集大小: 数据集越大,训练时间越长,所需的NCU越多。
- 训练精度: 要求更高的训练精度,通常需要更多的训练迭代次数,从而消耗更多的计算资源。
- 模型优化算法: 不同的优化算法对计算资源的需求也不同。
2. 使用模型
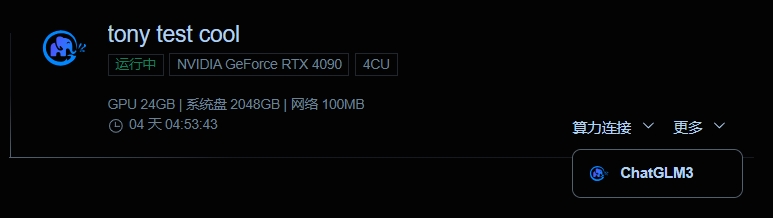
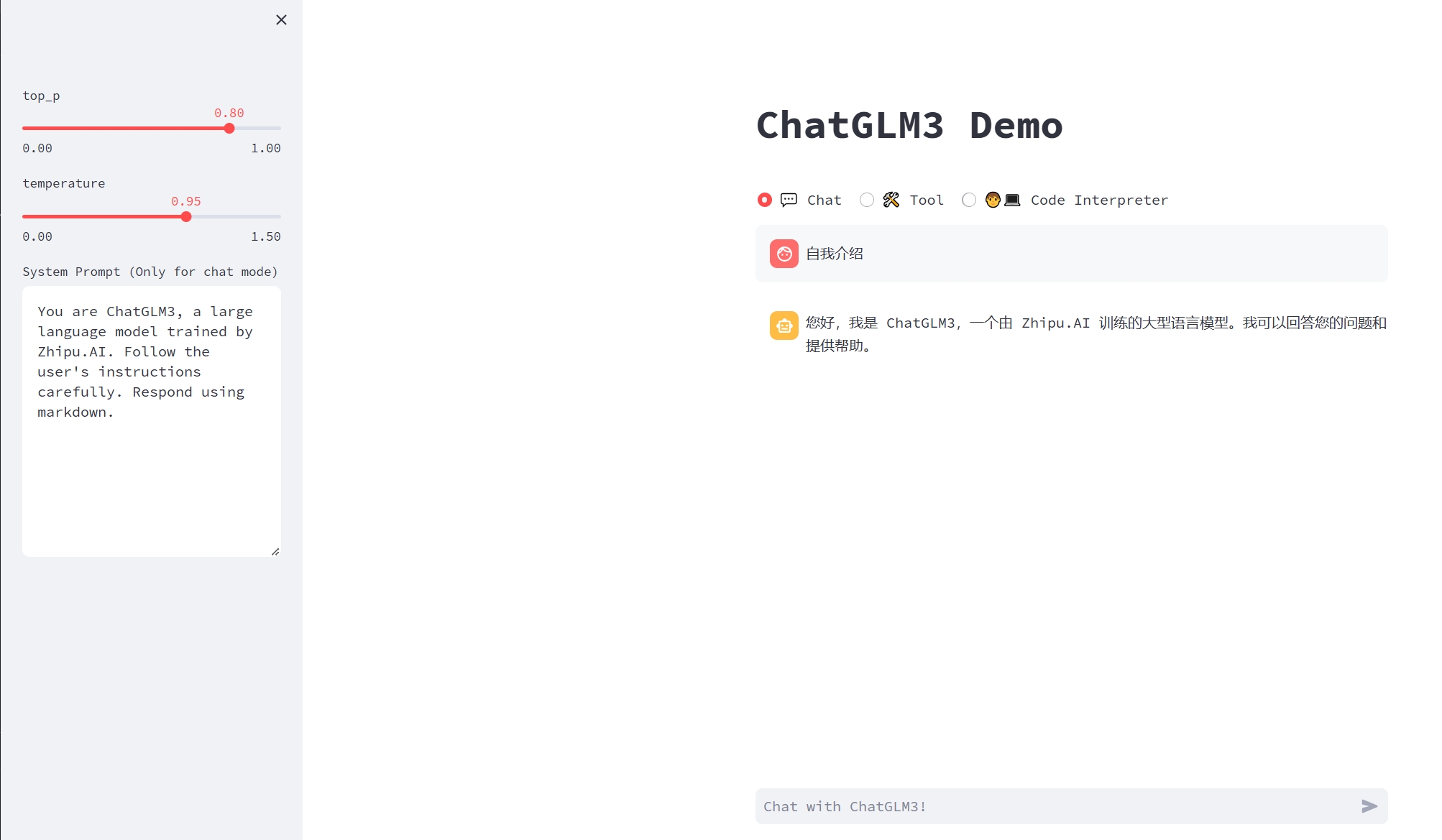
小明可以通过平台提供的算力接口,直接与运行在云端的 ChatGLM 模型进行交互,输入问题并获取答案。
3. 总结
通过共享算力平台,小明成功地将大型语言模型 ChatGLM 部署到云端,并实现了与模型的交互。 这让他可以更方便地探索和应用先进的自然语言处理技术。