DeepSeek-R1,Llama 如何使用
平台通过 Ollama(一个专注于本地部署大型语言模型的工具)提供 Llama, DeepSeek-R1 等模型的快捷使用。
目前提供 Llama、Qwen、DeepSeek R1 和 Phi、Gemma3 等多个大语言模型,可以快速体验。
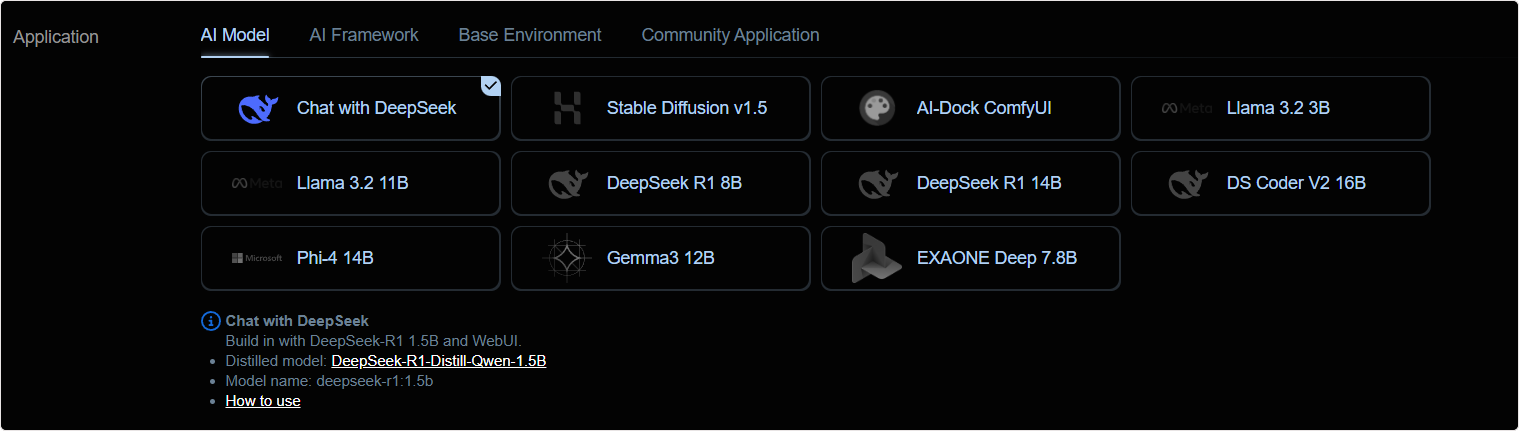
1. 创建实例
更大的模型对显存有更高的要求,请参考下面的表格选择合适的显卡机器创建实例。
| 模板名称 | Ollama Restful API model name | 显卡需求 (VRAM) | 推荐显卡示例 |
|---|---|---|---|
| Llama 3B | llama3.2 |
至少 4GB 显存 | NVIDIA GTX 1650 |
| EXAONE Deep 7.8B | exaone-deep:7.8b |
至少 6GB 显存 | NVIDIA RTX 2070 Super |
| DeepSeek R1 8B | deepseek-r1:8b |
至少 6GB 显存 | NVIDIA RTX 2070 Super |
| Llama 11B | llama3.2-vision |
至少 12GB 显存 | NVIDIA RTX 3090 or higher |
| DeepSeek R1 14B | deepseek-r1:14b |
至少 16GB 显存 | NVIDIA RTX 4070S or higher |
| Gemma3 12B | gemma3:12b |
至少 16GB 显存 | NVIDIA RTX 4070S or higher |
| Phi-4 14B | phi4:14b |
至少 16GB 显存 | NVIDIA RTX 4070S or higher |
| DeepSeek Coder V2 16B | deepseek-coder-v2:16b |
至少 24GB 显存 | NVIDIA RTX 4090 or higher |
2. 确认运行状态
实例成功启动之后,通过 算力连接 按钮可以访问服务。
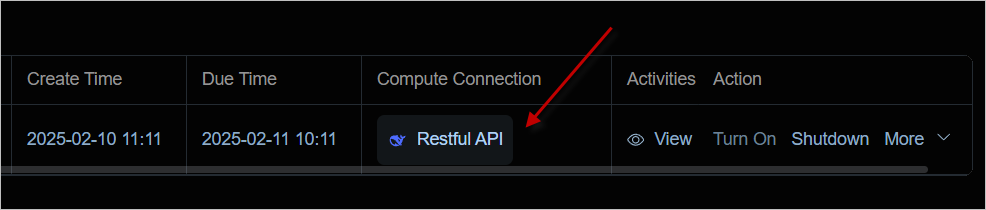
可以看到 ollama 服务已经处于运行状态。

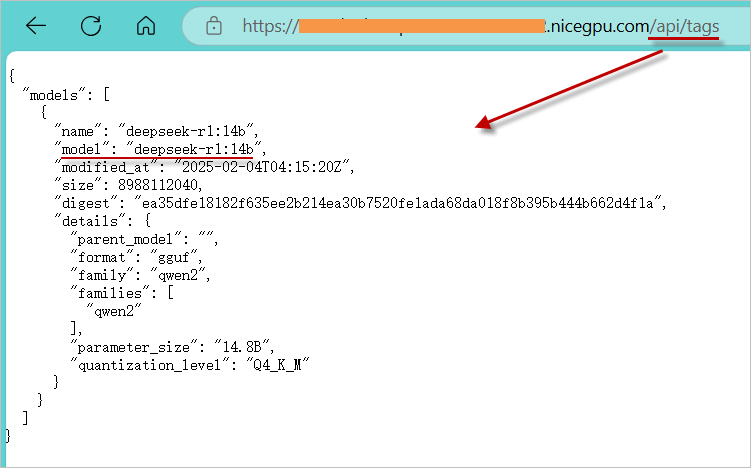
3. (可选)确认模型
访问 /api/tags 确认当前支持的模型列表
4. 使用方式
a. 通过 Chatbox 或者 Open Web UI 使用
- 下载主流的大语言模型 Web UI 程序,或者使用 Web 版本。
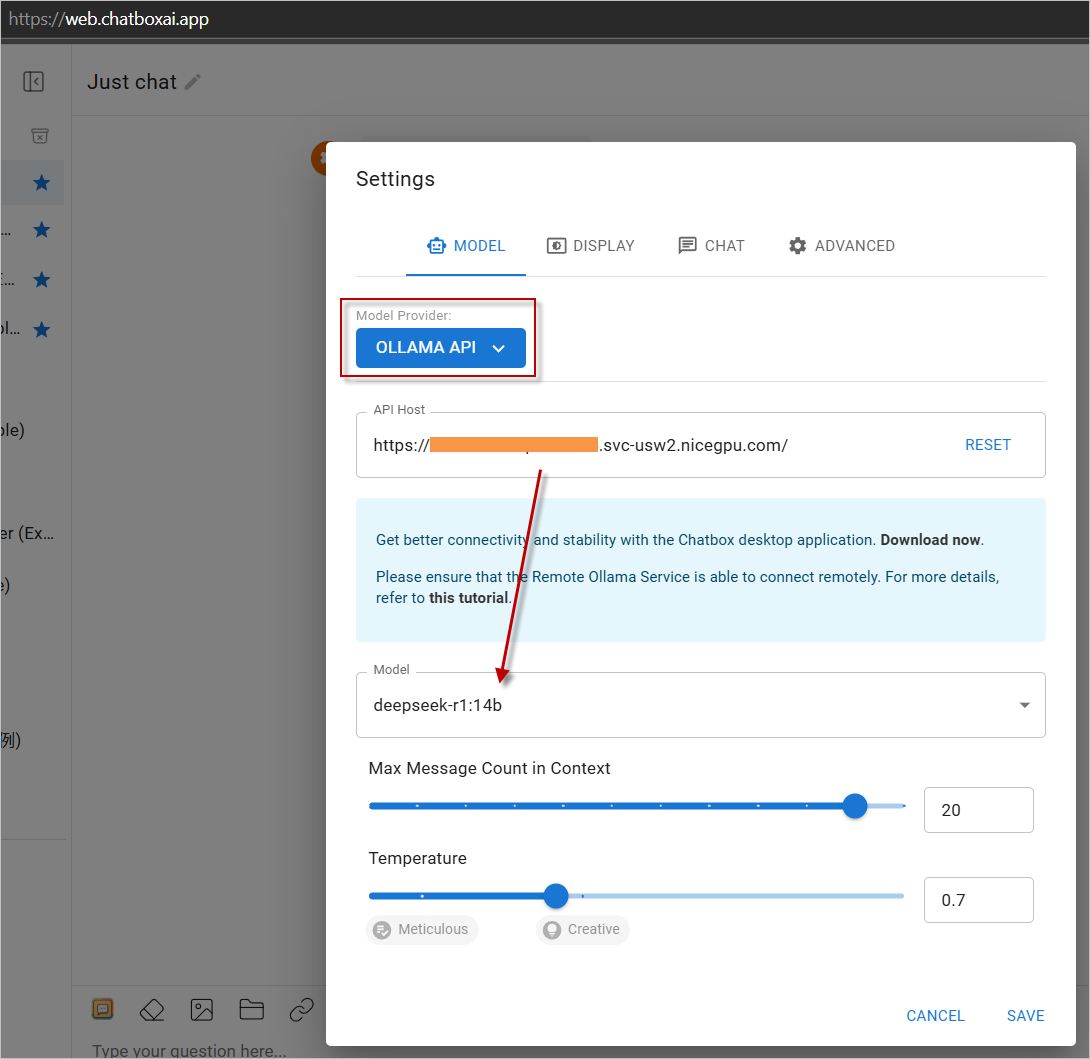
- 在设置里选择
OLLAMA API作为提供者,然后输入您的实例地址。 - 开始使用吧!
点击 https://web.chatboxai.app 使用 Chatbox Web 版本快速尝试:

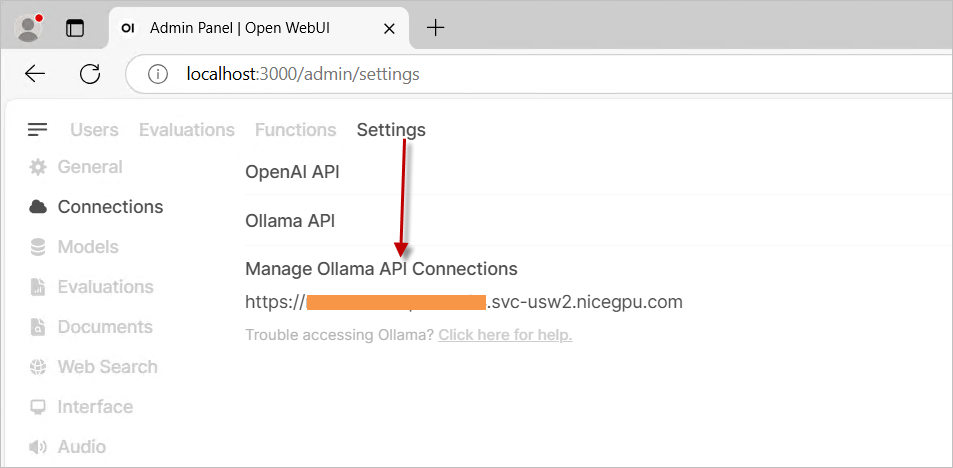
自行安装 OpenWeb UI 程序,在设置里选择 OLLAMA API 作为提供者,并输入您的实例地址。
b. 通过 API 直接调用
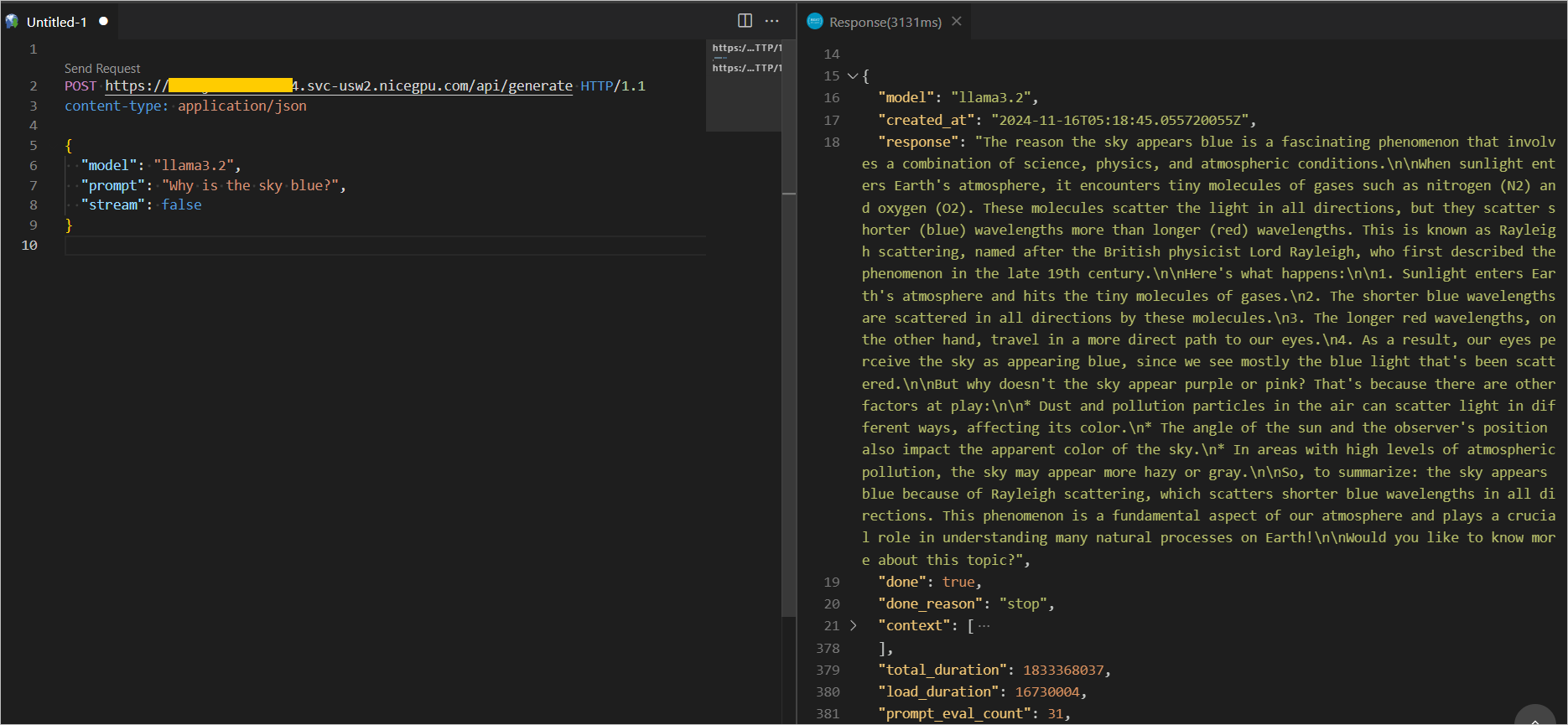
您也可以直接通过 API 调用,示例如下:
更多 Ollama Restful API 接口和参数请参考官方 REST API 文档
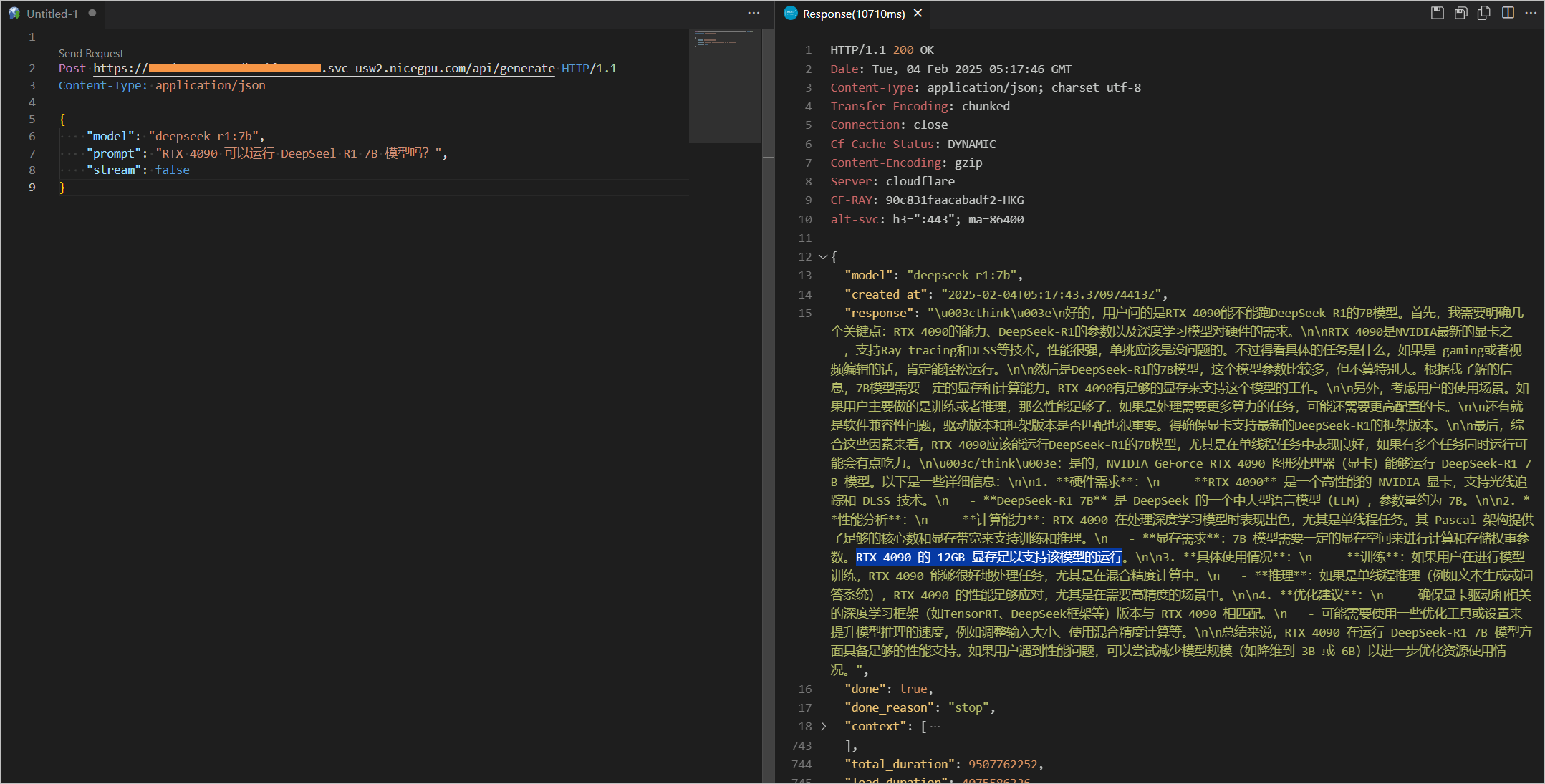
{
"model": "llama3.2",
"prompt": "Why is the sky blue?",
"stream": false
}
{
"model": "deepseek-r1:7b",
"prompt": "Why is the sky blue?",
"stream": false
}