AI创业公司 - 大模型训练
场景
一家专注于生成式 AI 的创业公司希望开发一款功能强大的文本生成模型,并将其作为 SaaS 服务提供给其他企业。
1. 注册并创建实例
公司在NiceGPU注册账号后,根据模型的规模和训练时长,申请了多个配置有高性能 GPU 的计算节点,并组成了一个 Ray 集群。

- 什么是NCU?
- 1 NCU 等于您可以在我们平台上连续使用24小时的一块A100 GPU的算力。
- AI创业公司通常涉及到更加复杂、大规模的AI模型训练和部署。因此,对算力需求也更为庞大。以下是一些典型场景的举例:
- 超大规模语言模型(LLM)训练:
- 任务: 训练类似GPT-3这样的大型语言模型,具备生成文本、翻译、写代码等多种能力。
- 所需NCU: 数百甚至数千NCU。LLM参数量巨大,训练数据量庞大,需要极大的算力支持。
- 场景: 开发通用型AI助手、智能客服、内容生成工具等。
- 多模态大模型训练:
- 任务: 训练能够处理文本、图像、视频等多种模态数据的模型。
- 所需NCU: 数百NCU。多模态模型涉及到多种数据类型,模型结构复杂,对算力要求较高。
- 场景: 开发AI绘画工具、视频生成工具、虚拟人等。
- 分布式训练:
- 任务: 将模型训练任务分布到多个GPU上,加速训练过程。
- 所需NCU: 根据模型规模和分布式策略而定,通常需要数十至数百NCU。
- 场景: 训练超大规模模型、加速实验迭代等。
- 影响NCU需求的因素,除了模型规模和数据量外,以下因素也会影响NCU的需求:
- 模型架构: Transformer模型、CNN模型等不同架构对计算资源的需求不同。
- 优化算法: 不同的优化算法对计算资源的利用效率不同。
- 硬件配置: GPU型号、内存大小等硬件配置会影响训练速度。
- 分布式策略: 数据并行、模型并行等不同的分布式策略对通信开销和计算资源的利用率有影响。
2. 准备数据和代码
- 数据准备: 公司收集了海量的文本数据,并将其清洗、预处理,形成适合模型训练的格式。
- 代码开发: 公司的 AI 工程师使用 PyTorch 和 Transformers 框架,基于 Transformer 架构,开发了大规模语言模型的训练代码。
3. 配置 Ray 集群
- 资源分配: 公司将计算节点的 CPU、GPU、内存等资源分配给 Ray 集群。
- 分布式策略: 公司利用 Ray 的分布式数据并行(DDP)和模型并行(MP)等技术,将模型和数据分块到多个 GPU 上,加速训练过程。
- 容错机制: 公司配置了 Ray 的容错机制,以保证训练任务在发生故障时能够自动恢复。
4. 启动训练任务
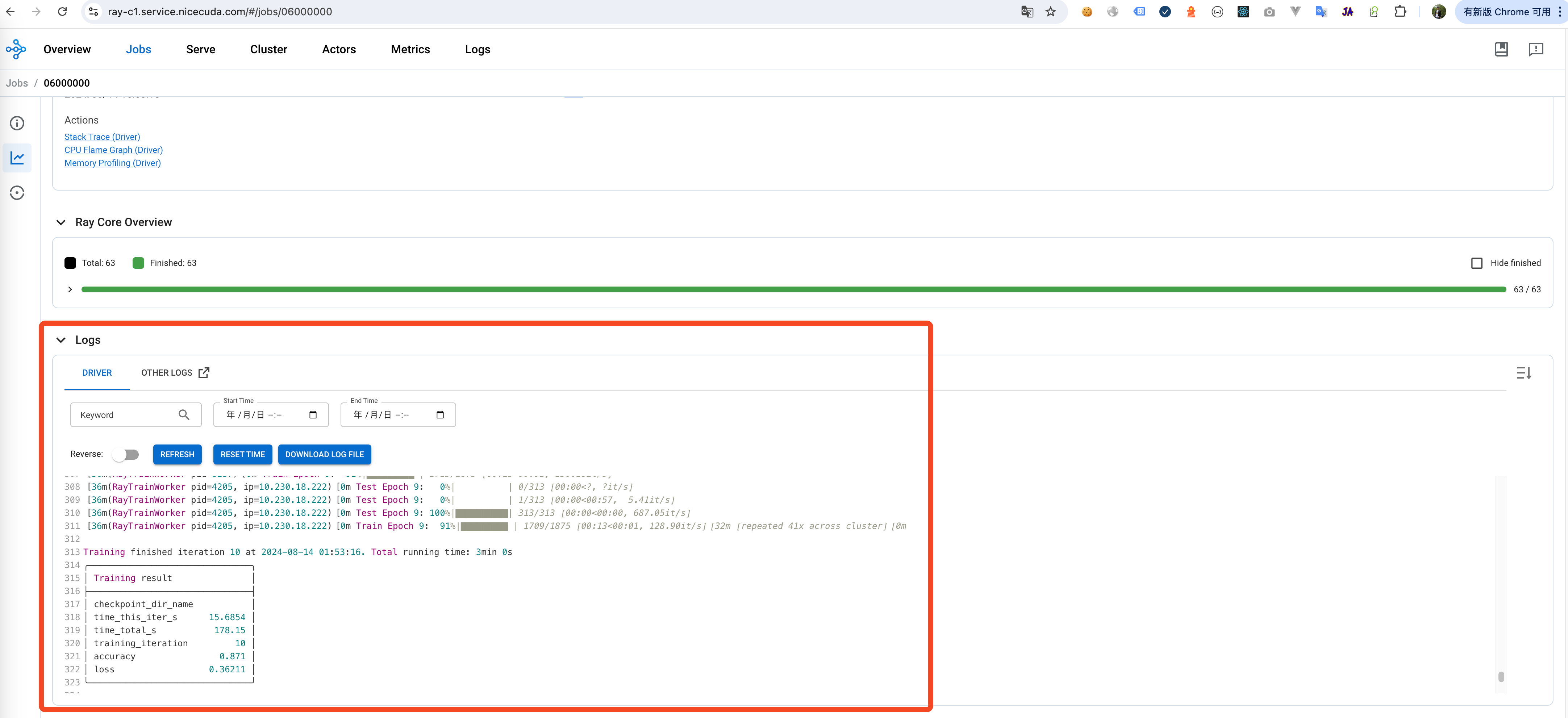
- 任务提交: 公司将训练任务提交到 Ray 集群,Ray 会自动调度任务,将计算负载分发到各个节点上。
- 监控训练过程: 公司通过 Ray 的监控面板实时监控训练进度,包括训练损失、困惑度等指标。
import ray from transformers import AutoModelForSeq2SeqLM # 连接到 Ray 集群 ray.init(address="auto") # 分布式数据并行 @ray.remote class TrainTask: def __init__(self, config, data_loader): self.model = AutoModelForSeq2SeqLM.from_config(config) self.data_loader = data_loader def train_epoch(self): # 训练一个 epoch 的代码 pass # ... (其余代码省略)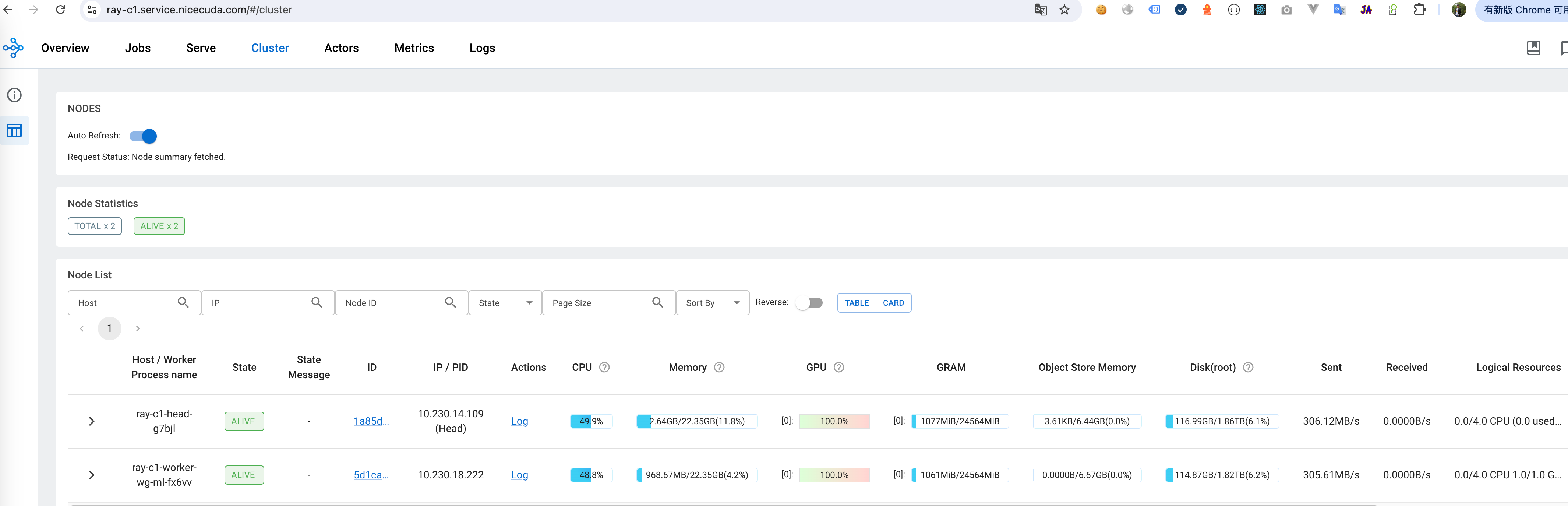
5. 模型保存和部署
- 模型保存: 训练完成后,公司将训练好的模型保存到云存储中。
- 模型部署: 公司使用 FastAPI 或 Flask 等框架,将模型部署为 RESTful API,对外提供服务。
- 容器化: 公司将模型服务容器化,并部署到容器编排平台(如 Kubernetes)上,实现自动伸缩和高可用。
6. 提供 SaaS 服务
- API 对外开放: 公司通过 API 网关对外开放模型服务,允许其他企业通过 API 调用模型,生成文本。
# 部署为 API 服务 from fastapi import FastAPI from transformers import pipeline app = FastAPI() generator = pipeline("text-generation", model="saved_model") @app.post("/generate") def generate_text(prompt: str): result = generator(prompt, max_length=100) return {"generated_text": result[0]["generated_text"]}
7. 总结
通过共享算力平台和 Ray 集群,这家 AI 创业公司成功地训练了一个大规模的语言模型,并将其部署为 SaaS 服务,实现了商业化。
这个案例展示了NiceGPU在 AI 模型训练和部署中的重要作用,为 AI 创业公司提供了快速、灵活、可扩展的解决方案。